
Les entrées sont classées par ordre alphabétique du nom de famille de l’orateur.
–
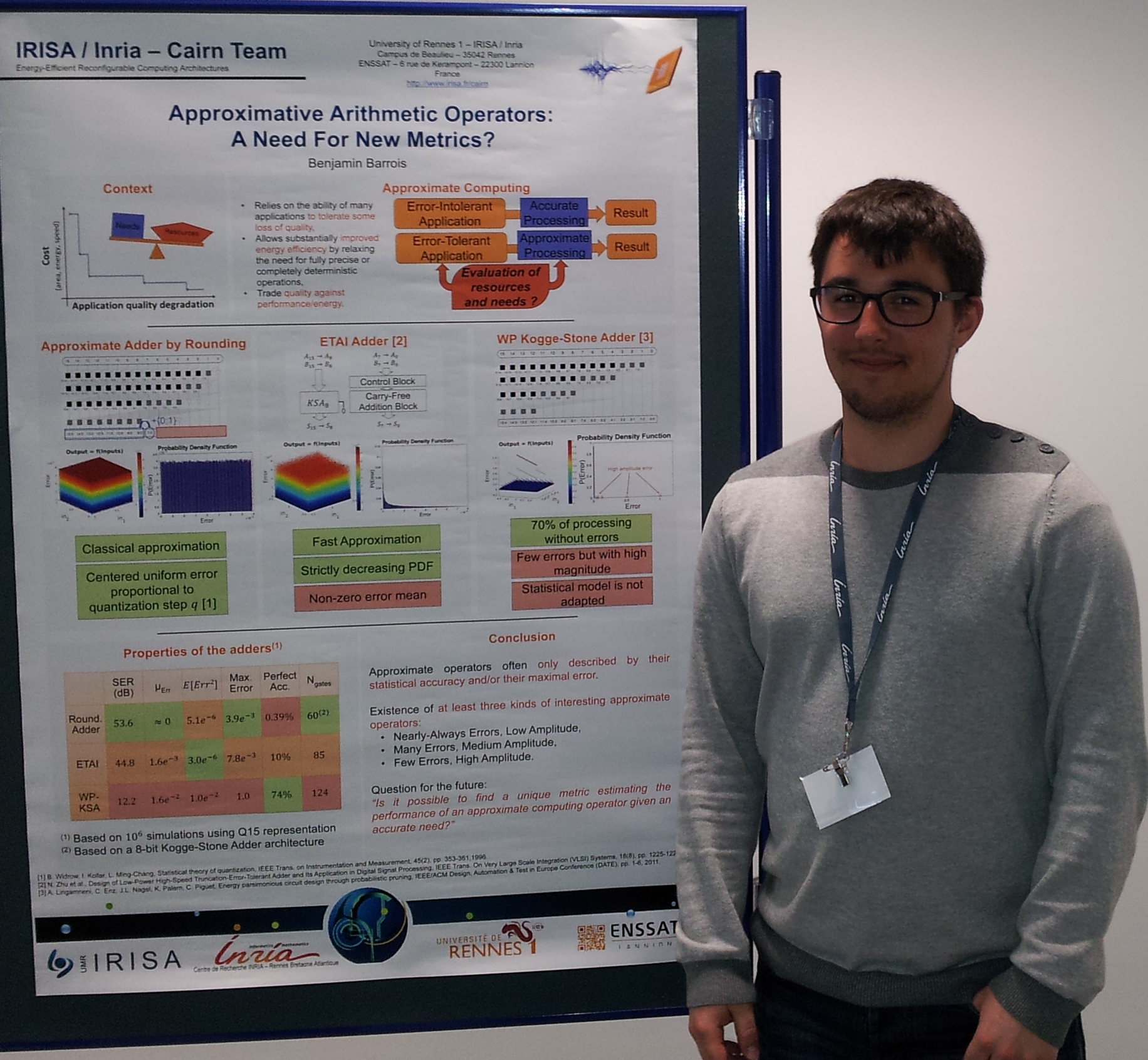
- POSTER : Approximative arithmetic operators: a need for new metrics?
- Benjamin Barrois – IRISA-UR1

- Résumé: With the rise of embedded systems, the need for low energy circuit has never been so crucial. The size of a silicon transistor being reaching its physical limits, improvements of energy consumption won’t be able to be made by manufacturing evolutions any more with today’s leading technology. That is why efforts have to be made to an arithmetical point of view in order to design more efficient circuit, and approximate computing is a very promising way to design architectures. Indeed, many applications are error-resilient, which means that a part of the computation accuracy can be traded against significant time, area and energy savings. The difficulty in the use of such architectures is the need to for the outside error to be handled. A classical way to create an approximated design is to use fixed-point arithmetic. This representation has the advantage of having a well-defined output error, which is known for being a uniform white noise, independently of the input signal. However, new operators are now trying to change the world of approximate computing. The question is: can we still use the same usual metrics to define these operators?
- Poster : Poster-Barrois-Benjamin
–
- EXPOSÉ et POSTER : Calcul modulaire en RNS pour les applications cryptographiques
- Karim Bigou – CNRS-IRSA


- Résumé: La représentation modulaire des nombres (ou RNS pour residue number system) permet de représenter les nombres en les découpant en morceaux indépendants grâce au théorème chinois des restes. Cette représentation est notamment utilisée pour accélérer les calculs sur les grands nombres en cryptographie asymétrique, et devient de plus en plus populaire pour cette application. Cet exposé présente les grandes lignes de l’utilisation du RNS pour la cryptographie et certaines de ses particularités. Des propositions d’accélération des calculs RNS issues de la thèse sont ensuite présentées, pour des contextes applicatifs spécifiques. Par exemple, des motifs de calcul efficaces pour l’exponentiation RSA sont présentés.
Présentation : Presentation-Bigou-Karim
Poster : https://hal.inria.fr/hal-01141347


–
- EXPOSÉ : Reproducible level 1 on massively parallel systems
- Chemseddine Chohra – DALI/LIRMM/UPVD

- Résumé: Modern high performance computation (HPC) performs a huge amount of floating point operations on massively multithreaded systems. Those systems interleave operations and include both dynamic scheduling and non-deterministic reductions that prevent numerical reproducibility, i.e. getting identical results from multiple runs, even on one given machine. Floating point addition is non-associative and the result depends on the computation order. Of course, numerical reproducibility is important to debug, check the correctness of programs and validate the results. A way to guarantee the numerical reproducibility is to calculate the correctly rounded value of the exact result, i.e. extending the IEEE-754 rounding properties to larger computing sequences. When such computation is possible, it is certainly more costly. But is it unacceptable in practice? We are motivated by round-to-nearest parallel BLAS. We can implement such RTN-BLAS thanks to recent algorithms that compute correctly rounded sums.
Our first results for reproducible level 1 BLAS in a shared memory computing environment has been presented at the international conference SCAN 2014. We have shown that for shared memory systems, we could evaluate rounded to nearest and reproducible sum or dot product with no important overcost. Now we present how to extend this approach to larger multisocket systems using hybrid programming with MPI + OpenMP and we study its performance.
Présentation : Presentation-Chohra-Chemseddine

–
- EXPOSÉ : Analyse efficace des systèmes linéaires multidimensionnels pour l’optimisation de l’implémentation en virgule fixe
- Gaël Deest – IRISA

- Résumé: Dans les systèmes embarqués, beaucoup d’algorithmes numériques sont implémentés en virgule fixe pour respecter les contraintes de surface et de consommation énergétique. Les choix d’encodage ont un impact significatif sur la consommation et la précision du système. Il en résulte un problème d’optimisation nécessitant une connaissance précise de la dynamique des opérandes d’une part, et une exploration approfondie de l’espace de recherche d’autre part afin de trouver un compromis coût/précision satisfaisant. L’évaluation de la précision, souvent implémentée par simulation, limite généralement la profondeur de cette exploration, ce qui amène à des compromis largement sous-optimaux. Les techniques analytiques résolvent partiellement ce problème pour une classe limitée d’applications uni-dimensionnelles. Dans ces travaux, nous montrons comment étendre ces méthodes aux filtres linéaires multi-dimensionnels (image, vidéo) en extrayant, à partir d’une spécification logicielle, une représentation concise du programme. Cette représentation est ensuite exploitée pour estimer la réponse impulsionelle du système, utilisée tant pour l’estimation de la dynamique que pour l’évaluation de la précision.
- Présentation : Presentation-Deest-Gael

–
- COURS : Algorithmes d’échantillonnages haute précision sur les réseaux euclidiens et leur rôle en cryptographie
- Leo Ducas – CWI Amsterdam.

- Résumé: La cryptographie fondée sur les réseaux euclidiens à ceci de particulier, qu’elle fait appel à des distributions non uniformes sur des ensembles infinis. De plus, ces distributions doivent être échantillonnées avec une précision suffisante pour se prémunir contre des attaques statistiques. Les contraintes d’efficacités sur petites et moyennes architectures rendent ce problème algorithmique intéressant.
Dans cet exposé, nous présenterons quelques techniques du domaine, incluant des automates probabilistes, et une approche combinatoires.
Présentation : Presentation-Ducas-Leo
Vidéo du cours : lien vers la vidéo

–
- EXPOSÉ : Validation numérique haute performance avec l’arithmétique stochastique
- Pacôme Eberhart – LIP6.

- Résumé:Dans le contexte du calcul scientifique haute performance, la validation numérique est de plus en plus importante du fait du développement du parallélisme et de l’augmentation de la quantité de calculs effectués. Notre approche pour la validation numérique, l’arithmétique stochastique discrète, implémentée dans la bibliothèque CADNA, avait jusqu’à maintenant un surcoût à l’exécution élevé (particulièrement pour les applications hautes performances) et ne permettait pas de tirer parti des unités vectorielles. Nous présentons ici une nouvelle version de CADNA qui réduit ce surcoût (jusqu’à 87%) à la fois pour des noyaux de calcul simples et pour des problèmes plus réalistes. Cette nouvelle version permet aussi l’utilisation d’instructions vectorielles, pour un gain de performance allant jusqu’à un facteur 5.63 en simple précision sur AVX2.
Présentation : Presentation-Eberhart-Pacome

–
- EXPOSÉ + DÉMO : L’arithmétique stochastique sans recompiler
- François Févotte – EDF

- Résumé: EDF développe et utilise un grand nombre d’applications utilisant la simulation numérique. Dans le cadre des processus de
Validation&Vérification, EDF souhaite évaluer l’impact de l’arithmétique flottante sur la qualité des résultats fournis. Parmi les outils existants, CADNA implémentant l’arithmétique stochastique discrète permet d’auditer un code sans avoir à modifier les algorithmes mais nécessite de
modifier les codes sources. Cela rend le coût d’entrée élevé pour le développeur et son utilisation pour lors impossible lorsque l’on utilise des bibliothèques externes dont on n’a pas accès aux sources. Pour faire face à ces limitations, EDF étudie avec Verrou la possibilité d’implémenter l’arithmétique stochastique en partant de l’exécutable sous sa forme binaire.
Présentation : Presentation-Fevotte-Francois

–
- EXPOSÉ : The Parks McClellan algorithm: a scalable approach for designing FIR filters
- Silviu Filip – AriC/LIP

- Résumé: Based on the theory of minimax polynomial approximation, the Parks-McClellan algorithm is one of the most well-known approaches for designing finite impulse response filters. In this talk, I will give new insights on the practical behavior of this algorithm. The main ideas I will be focusing on are barycentric interpolation methods and numerically stable root finding routines that rely on determining the eigenvalues of appropriate structured matrices. Barycentric interpolation and eigenvalue-based rootfinders have garnered a lot of interest from numerical analysts in the last fifteen years. I will explain how these building blocks can be used to write an efficient implementation of the aforementioned algorithm, and showcase its robustness by comparing it to other filter design routines found inside widely used software environments, like Matlab and Scipy.
Présentation : Presentation-Filip-Silviu

–
- POSTER : Accélérateur(s) matériel(s) pour HECC
- Gabriel Gallin – CNRS-IRISA

- Résumé: Dans le cadre du projet inter-labex HAH (Hardware and Arithmetic for Hyperelliptic Curves Cryptography), nous étudions l’extension d’accélérateurs de calcul en cryptographie sur courbes elliptiques (ECC) au cas des courbes hyper-elliptiques (HECC). L’un de nos objectifs dans ce projet est de fournir à la fois des opérateurs arithmétiques et des architectures de calcul optimisées en vitesse, à faible coût (surface de circuit et/ou énergie) et enfin robustes contre certaines attaques par canaux cachés (par observation et par perturbation).
- Poster : https://hal.inria.fr/hal-01134020

–
- EXPOSÉ : Reproducibility and Accuracy for High-Performance Computing
- Roman Iakymchuk – LIP6

- Résumé: On modern multi-core, many-core, and heterogeneous architectures, floating-point computations, especially reductions, may become non-deterministic and, therefore, non-reproducible mainly due to the non-associativity of floating-point operations. We introduce an approach to compute the correctly rounded sums of large floating-point vectors accurately and efficiently, achieving deterministic results by construction. Our multi-level algorithm consists of two main stages: a filtering stage that relies on fast vectorized floating-point expansions, and an accumulation stage based on superaccumulators in a high-radix carry-save representation. We extend this approach to dot product and matrix-matrix multiplication.
In this talk, I will present the reproducible and accurate (rounding to the nearest) algorithms for summation, dot product, and matrix-matrix multiplication as well as their implementations in parallel environments such as Intel server CPUs, Intel Xeon Phi, and both NVIDIA and AMD GPUs. I will show that the performance of our algorithms is comparable with the standard implementations.
Présentation : https://hal.archives-ouvertes.fr/hal-01140531/file/raim2015.pdf

–
- POSTER : ExBLAS: Reproducible and Accurate BLAS Library
- Roman Iakymchuk – LIP6

- Résumé: Due to non-associativity of floating-point operations and dynamic scheduling on parallel architectures, getting a bitwise reproducible floating-point result for multiple executions of the same code on different or even similar parallel architectures is challenging. We address the problem of reproducibility in the context of fundamental linear algebra operations — like the ones included in the Basic Linear Algebra Subprograms (BLAS) library — and propose algorithms that yields both reproducible and accurate (rounding to the nearest) results. We present implementations of these reproducible and accurate algorithms for the BLAS routines in parallel environments such as Intel server CPUs, Intel Xeon Phi, and both NVIDIA and AMD GPUs. We show that the performance of our implementations is comparable to the standard ones.
- Poster : https://hal.archives-ouvertes.fr/hal-01140280/document

–
- POSTER : Filters computing just right
- Matei Istoan – INSA Lyon, CITI Lab

- Résumé: Many digital filters and signal-processing transforms can be expressed as a sum of products with constants (SPC). This poster presents the automatic construction of low-precision, but high accuracy FIR filter architectures: these architectures are specified as last-bit accurate with respect to a mathematical definition. In other words, they behave as if the computation was performed with infinite accuracy, then rounded only once to the low-precision output format. This eases the task of porting double-precision code (e.g. Matlab) to low-precision hardware or FPGA. The construction of the most efficient architectures obeying such a specification, introducing several architectural improvements to this purpose is also presented. This approach is demonstrated in a generic, open-source architecture generator tool built upon the FloPoCo framework.
Poster : Poster-Istoan-Matei

–
- EXPOSÉ : RNS Arithmetic for Linear Algebra of Discrete Logarithm Computations Using Parallel Architectures
- Hamza Jeljeli – LORIA

- Résumé: In cryptanalysis, computing discrete logarithm problem (DLP) in multiplicative subgroups of finite fields using index-calculus-based methods requires solving large sparse systems of linear equations over finite fields of large characteristic. We run these linear algebra computations on GPU- and multi-core-based clusters. In this talk, we will describe the different levels of parallelism that can be exploited in these computations and will focus on the arithmetic aspects. We will show how the use of the Residue Number System (RNS) representation with architectures that exploit data level parallelism such that GPUs or CPUs featuring SIMD instructions accelerate the arithmetic over finite fields of large characteristic. We will illustrate our approach with record-sized DLP computations.
Présentation : Presentation-Jeljeli-Hamza

–
- EXPOSÉ + DÉMO : Metalibm: génération de fonctions mathématiques
- Olga Kupriianova – LIP6

- Résumé: Les ensembles de codes pour évaluer les fonctions mathématiques dans un langage de programmation sont les bibliothèques mathématiques (libms). Il existe plusieurs versions de ces libm, écrites par de différentes équipes, munies d’implantations de fonctions différentes (ex.: arrondi correct dans crlibm, les fonctions pour langage C dans glibc libm). Cependant, les libms standards ont été généralisées au maximum: pour fournir les fonctions à tout le monde. Donc, les domaines de définition de fonctions sont aussi large que possible, ce qui nécessite un
traitement des cas spéciaux (Inf, NaN, etc) pour chaque domaine. Chaque fonction dans libm est évaluée par le même code: il n’y a pas de choix entre réalisations rapide ou précise.
Nous proposons de réécrire la libm dans une façon plus flexible: on va avoir des implantations mieux adaptées pour un ensemble des paramètres, parmi lesquels il y a la domaine d’évaluation et la précision finale de résultat. Au lieu de réécrire les milliers des variations pour chaque fonction nous proposons de générer des implantations paramétrées. En plus, notre générateur de code (Metalibm-lutetia) peut être considéré black-box: la fonction elle-même est aussi un paramètre. Pendant la génération de fonctions, Metalibm peut faire la réduction d’arguments spécifique en détectant les propriétés algébrique ou faire le découpage de domaine pour avoir les approximations polynomiales de degré borné. Nous avons commencé aussi des recherches sur la génération de fonctions vectorisées. - Présentation : Presentation-Kupriianova-Olga

–
- AG : Assemblée générale du GT Arith
- Philippe Langlois – Université Perpignan, DALI, LIRMM

- Résumé: bilan 2015
Rappels sur la structuration
RAIM 2015
Discussion autour de l’organisation des futures éditions des RAIM
Animation du GT Arith
Proposition pour les RAIM 2016 (début septembre autour de Perpignan)
Point divers

–
- EXPOSÉ : Calcul de la fonction thêta de Jacobi en temps quasi-optimal
- Hugo Labrande – LORIA/INRIA Nancy, University of Calgary

- Résumé: Connue et étudiée depuis plusieurs siècles par les mathématiciens, la fonction thêta de Jacobi Theta(z, tau) est une fonction à deux variables complexes ; son étude révèle un nombre remarquable de propriétés. Cette fonction intervient dans l’étude des formes modulaires, et celle des variétés algébriques complexes ; on la retrouve aussi dans certains algorithmes liés à la cryptographie sur les courbes elliptiques. Les valeurs Theta(0, tau), Theta(1/2, tau) et Theta(tau/2, tau), que l’on nomme thêta-constantes, apparaissent aussi dans une grande variété d’applications : par exemple, on peut s’en servir pour calculer le polynôme de classe de Hilbert, et ainsi générer des courbes elliptiques sûres cryptographiquement. Elles ont également des liens très forts avec la moyenne arithmético-géométrique de Gauss : c’est ce qu’utilise un algorithme de Dupont (2006) pour calculer ces valeurs à précision P bits en O(M(P) \log P) opérations sur les bits, ce qui est quasi-optimal. Nous proposons un algorithme permettant de calculer n’importe quelle valeur Theta(z, tau) à précision P avec la même complexité asymptotique quasi-optimale. Notre travail repose sur l’étude d’une certaine extension de la moyenne arithmético-géométrique ; il s’accompagne d’une implantation qui confirme les gains conséquents de cette méthode par rapport à l’état de l’art.
Présentation : Presentation-Labrande-Hugo

–
- EXPOSÉ : Optimisation des largeurs pour l’implantation des filtres linéaires en arithmétique virgule fixe
- Benoit Lopez – LIP6

Thèse soutenue en novembre 2014 - Résumé: Les systèmes électroniques autonomes sont de plus en plus présents dans notre quotidien. Un grand nombre d’entre eux embarque des applications issues du traitement du signal, notamment pour les opérations de communication. Les filtres, dont les filtres linéaires, en sont les briques de base. Le besoin d’autonomie de ces systèmes embarqués impliquent la nécessité d’en diminuer les ressources matérielles et cela peut passer par l’utilisation de l’arithmétique virgule fixe. Cette arithmétique, utilisant les nombres entiers, permet une plus grande modularité dans la représentation des nombres si on se permet d’utiliser des largeurs de données différentes suivant les chemins de données (sur FPGA ou ASIC). Bien entendu, de plus faibles largeurs entrainent de plus grandes erreurs de quantification et de calcul. Dans cet exposé, nous proposons une analyse de l’impact des erreurs de précisions sur la sortie du filtre en fonction des largeurs utilisées, ainsi qu’une formalisation du problème d’optimisation induit, où l’on cherchera à minimiser ces largeurs (donc à diminuer la surface et la consommation) sous une contrainte de précision sur la sortie du filtre.
- Présentation: Presentation-Lopez-Benoit

–
- EXPOSÉ : Fuzzy Arithmetic on GPU
- Manuel Marin – LIRMM/UPVD

- Résumé: Fuzzy arithmetic is useful to handle uncertainty in data. They usually rely on costly interval arithmetic based on lower-upper representation. In some cases, fuzzy numbers are symmetrical. We will show how we can exploit this property to halve the amount of operations and memory needed and increase accuracy as well, thanks to the midpoint-increment representation format. We will describe how we implemented this format into a fuzzy arithmetic library, specifically tuned to run on Graphic Processing Units (GPU). The results of a series of tests using compute-bound and memory-bound benchmarks show that the proposed format provides a performance gain of two to twenty over the lower-upper format.
- Présentation : https://hal.archives-ouvertes.fr/hal-01140504

–
- EXPOSÉ : Architecture hardware pour l’algorithme de Montgomery
- Amine Mrabet – Univ. Paris 8

- Résumé: J’ai utilisé la méthode CIOS (Coarsely Integrated Operand Scanning) présentée dans [1] combinée avec une architecture systolique pour implémenter Montgomery sur FPGA. L’architecture implémentée est évolutive pour les différents niveaux de sécurité avec le même nombre de cycles d’horloge.
[1] Cetin Kaya Koc, Tolga Acar and Burton S. Kaliski Jr. Analyzing and Comparing Montgomery Multiplication Algorithms, 1996.
Présentation : Presentation-Mrabet-Amine

–
- EXPOSE : Briques de base d’algèbre linéaire en arithmétique à virgule fixe
- Amine Najahi – DALI/LIRMM/UPVD

- Résumé:Afin de réduire les couts des systèmes embarqués, les programmeurs utilisent l’arithmétique à virgule fixe qui est plus adaptée aux processeurs dépourvus d’unités flottantes. Cependant, la programmation en virgule fixe est fastidieuse car elle nécessite de gérer à la main tous les détails arithmétiques.
Dans cette présentation, nous exposons une méthodologie pour générer automatiquement des programmes en virgule fixe qui soient certifiés du point de vue numérique. Dans une seconde partie, nous montrons comment utiliser ce cadre afin de générer du code pour l’inversion de matrices. - Présentation: Presentation-Najahi-Amine

–
- COURS : Recent Advances in Parallel Implementations of Scalar Multiplication over Binary Elliptic Curves
- Christophe Nègre – DALI/UPVD/LIRMM

- Résumé: The scalar multiplication is the main operation of cryptographic protocols based on elliptic curve. In the past few years, software implementations of scalar multiplication over binary elliptic curves have made some important progress. The new generations of Intel processors (Core i3,i5,7) provide a new instruction PCLMULQDQ which computes the product of 64bit binary polynomials which makes possible to speed-up the arithmetic in GF(2^m). The other improvements are due to new approaches for parallel implementation. We will review some recent results on parallel implementations based on GLV/GLS approach and on point halving.
- Présentation : https://hal.archives-ouvertes.fr/hal-01141628
Vidéo du cours : lien vers la vidéo

–
- EXPOSÉ : Solutions pour assurer la reproductibilité numérique de la simulation de l’effet des vagues sur les côtes
- Rafife Nheili – DALI/UPVD/LIRMM

- Résumé: The lack of numerical reproducibility for parallel floating-point computations is a stringent problem for HPC numerical simulations. Reproducibility is indeed desirable for code verification, testing, debugging and even for certification authority agreement. We describe and analyse strategies towards numerically reproducible simulations with a well known open source software for computational fluid dynamics.
- Présentation : Presentation-Nheili-Rafife

–
- EXPOSÉ : Calculs avec des nombres à virgule flottante paramétrés par la précision
- Antoine Plet – AriC-LIP

- Résumé: Au cours des calculs en arithmétique flottante, chaque opération de base introduit une erreur relative. Dès que les opérations s’enchaînent, cette erreur relative peut devenir importante et même dépasser 1. C’est pourquoi les algorithmes calculant sur des nombres à virgule flottante devraient toujours être accompagnés d’une analyse d’erreur, fournissant une borne sur l’erreur relative entachant le résultat final. Idéalement, on souhaiterait trouver une borne optimale : l’optimalité peut être démontrée à l’aide d’exemples paramétrés par la base et/ou la précision. Dans ce cas, les calculs doivent être menés à la main ce qui demande du temps et favorise les erreurs de calcul. Nous proposons deux méthodes pour calculer des additions et multiplications, dans un environnement de calcul formel, sur un certain type de nombres à virgule flottante paramétrés par la précision.
La première sépare l’opération exacte de l’arrondi, et se fonde sur la manière naturelle d’arrondir un nombre : on localise d’abord le chiffre de poids fort, puis on en déduit le chiffre de poids faible et
on peut finalement choisir comment l’arrondi se comporte.
La seconde méthode utilise le principe d’évaluation-interpolation. Elle est basée sur un lien entre les nombres flottants manipulés et les polynômes univariés : on peut évaluer le résultat de l’opération pour
plusieurs précisions puis en déduire le résultat paramétré par la précision en interpolant. Cette méthode repose sur un théorème qui assure la conservation du caractère « représentable par un polynôme » au
travers de l’arrondi (au plus proche, vers la mantisse paire). Ces deux méthodes sont implantées en Maple et ont permis de vérifier des calculs de la littérature. - Présentation : Presentation-Plet-Antoine

–
- EXPOSÉ : CAMPARY (CudA Multiple Precision ARithmetic librarY)
- Valentina Popescu – AriC/LIP

- Résumé: Nowadays, the most common way of representing real numbers in a computer is the binary floating-point (FP) format. The single (binary32) and double (binary64) formats are the most common, specified by the IEEE 754-2008 standard together with basic arithmetic operations (+,-,*,/,sqrt()) or rounding modes. However, many numerical problems require a higher computing precision (several hundred bits) than the one offered by these standard formats. One common way of extending the precision is to represent numbers in a multiple-term format. By using the so-called floating-point expansions, real numbers are represented as the unevaluated sum of standard machine precision FP numbers. Such a representation is possible thanks to the availability of error-free transforms. These are algorithms for computing the error of a FP addition or multiplication exactly, taking the rounding mode into account and using directly available, hardware implemented FP operations.
In this talk, we present CAMPARY (CudA Multiple Precision ARithmetic librarY), a multiple-precision floating-point arithmetic library developed in the CUDA programming language for the NVIDIA GPU platform, that uses the multiple-term approach. We provide support for all basic arithmetic operations, but here we will focus on a new normalization algorithm. This operation is very important when FP expansions are used, since it ensures certain precision related requirements and allows for a more compact representation. Finally, we present a new method for computing the reciprocal and the square root of a FP expansion based on an adapted Newton-Raphson iteration where the intermediate calculations are done using « truncated » operations (additions, multiplications) involving FP expansions. - Présentation : Presentation-Popescu-Valentina

–
- DÉMO + POSTER : ID.Fix: AN EDA TOOL FOR FIXED-POINT REFINEMENT OF EMBEDDED SYSTEMS
- Nicolas Simon – INRIA-IRISA

- Résumé: Most of digital image and signal processing algorithms are implemented into architectures based on fixed-point arithmetic to satisfy cost and power consumption constraints associated with most of embedded and cyber-physical systems. The fixed-point conversion process (or refinement) is crucial for reducing the time-to-market and design tools to automate this phase and to explore the design space are still lacking. The ID.Fix EDA tool, based on the compiler infrastructure GECOS, allows for the conversion of a floating-point C source code into a C code using fixed-point data types. The data word-lengths are optimized by minimizing the implementation cost under accuracy constraint. To achieve low optimization time, an analytical approach is used to evaluate the fixed-point computation accuracy. This approach is valid for systems made-up of any smooth arithmetic operations. Commercial tools can then be used to synthesize the architecture or to perform software compilation from the output fixed-point description of the application. Thus, the goal is to bridge the gap between the floating-point description developed by algorithm designer and the fixed-point description use as input for high-level synthesis or compilation tools.

–
- EXPOSÉ : Synthèse de code avec compromis entre performance et précision en arithmétique flottante IEEE 754
- Laurent Thévenoux – LIRMM/UPVD

- Thèse soutenue en juillet 2014
- Résumé: La précision numérique et le temps d’exécution des programmes utilisant l’arithmétique flottante sont des enjeux majeurs dans de nombreuses applications de l’informatique. L’amélioration de ces critères fait l’objet de nombreux travaux de recherche. Cependant, nous constatons que l’amélioration de la précision diminue les performances et inversement. En effet, les techniques d’amélioration de la précision, telles que les expansions ou les compensations, augmentent le nombre de calculs que devra exécuter un programme. Plus ce coût est élevé, plus les performances sont diminuées. Ce travail de thèse présente une méthode d’amélioration automatique de la précision prenant en compte l’effet négatif sur les performances. Pour cela nous automatisons les transformations sans erreur des opérations élémentaires car cette technique présente un fort potentiel de parallélisme. Nous proposons de plus des stratégies d’optimisation permettant une amélioration partielle des programmes afin de contrôler plus finement son impact sur les performances. Des compromis entre performances et précision sont alors assurés par la synthèse de code. Nous présentons de plus, à l’aide d’outils implantant toutes les contributions de ce travail, de nombreux résultats expérimentaux.
- Présentation : Presentation-Thevenoux-Laurent
